Kubernetes Design Patterns
This is not a topic identified in the Kubernetes Certified Administrator Exam Curriculum. Nonetheless I found that understanding the evolving Design Patterns are very helpful in finding quick solutions to cluster design, and provide a simplified framework for thinking.
When searching specifically for the topic I found that Brendan Burns and David Oppenheimer were some of the first to write about them. The following slide show is the source ( https://www.usenix.org/sites/default/files/conference/protected-files/hotcloud16_slides_burns.pdf ) .
This set of articles on Microsoft are also a great introduction to Cloud Design Patterns
The following are a couple of design patterns identified.
Single-node multi-container patterns
● Sidecar
● Ambasador
● Adapter
Distributed container patterns
● Leader election
● Work queue
● Scatter/gather
Sidecar Design Pattern
from https://docs.microsoft.com/en-us/azure/architecture/patterns/sidecar
This pattern is named Sidecar because it resembles a sidecar attached to a motorcycle. In the pattern, the sidecar is attached to a parent application and provides supporting features for the application. The sidecar also shares the same lifecycle as the parent application, being created and retired alongside the parent. The sidecar pattern is sometimes referred to as the sidekick pattern and is a decomposition pattern.
Context and Problem
Applications and services often require related functionality, such as monitoring, logging, configuration, and networking services. These peripheral tasks can be implemented as separate components or services.
If they are tightly integrated into the application, they can run in the same process as the application, making efficient use of shared resources. However, this also means they are not well isolated, and an outage in one of these components can affect other components or the entire application. Also, they usually need to be implemented using the same language as the parent application. As a result, the component and the application have close interdependence on each other.
If the application is decomposed into services, then each service can be built using different languages and technologies. While this gives more flexibility, it means that each component has its own dependencies and requires language-specific libraries to access the underlying platform and any resources shared with the parent application. In addition, deploying these features as separate services can add latency to the application. Managing the code and dependencies for these language-specific interfaces can also add considerable complexity, especially for hosting, deployment, and management.
Solution
Co-locate a cohesive set of tasks with the primary application, but place them inside their own process or container, providing a homogeneous interface for platform services across languages.
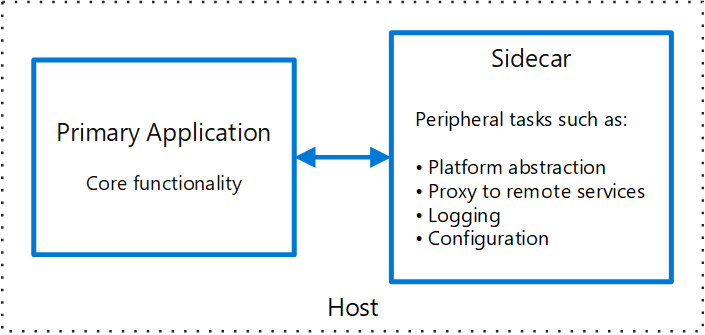
A sidecar service is not necessarily part of the application, but is connected to it. It goes wherever the parent application goes. Sidecars are supporting processes or services that are deployed with the primary application. On a motorcycle, the sidecar is attached to one motorcycle, and each motorcycle can have its own sidecar. In the same way, a sidecar service shares the fate of its parent application. For each instance of the application, an instance of the sidecar is deployed and hosted alongside it.
Advantages of using a sidecar pattern include:
A sidecar is independent from its primary application in terms of runtime environment and programming language, so you don't need to develop one sidecar per language.
The sidecar can access the same resources as the primary application. For example, a sidecar can monitor system resources used by both the sidecar and the primary application.
Because of its proximity to the primary application, there’s no significant latency when communicating between them.
Even for applications that don’t provide an extensibility mechanism, you can use a sidecar to extend functionality by attaching it as own process in the same host or sub-container as the primary application.
The sidecar pattern is often used with containers and referred to as a sidecar container or sidekick container.
Issues and Considerations
- Consider the deployment and packaging format you will use to deploy services, processes, or containers. Containers are particularly well suited to the sidecar pattern.
- When designing a sidecar service, carefully decide on the interprocess communication mechanism. Try to use language- or framework-agnostic technologies unless performance requirements make that impractical.
- Before putting functionality into a sidecar, consider whether it would work better as a separate service or a more traditional daemon.
- Also consider whether the functionality could be implemented as a library or using a traditional extension mechanism. Language-specific libraries may have a deeper level of integration and less network overhead.
When to Use this Pattern
Use this pattern when:
- Your primary application uses a heterogenous set of languages and frameworks. A component located in a sidecar service can be consumed by applications written in different languages using different frameworks.
- A component is owned by a remote team or a different organization.
- A component or feature must be co-located on the same host as the application
- You need a service that shares the overall lifecycle of your main application, but can be independently updated.
- You need fine-grained control over resource limits for a particular resource or component. For example, you may want to restrict the amount of memory a specific component uses. You can deploy the component as a sidecar and manage memory usage independently of the main application.
This pattern may not be suitable:
- When interprocess communication needs to be optimized. Communication between a parent application and sidecar services includes some overhead, notably latency in the calls. This may not be an acceptable trade-off for chatty interfaces.
- For small applications where the resource cost of deploying a sidecar service for each instance is not worth the advantage of isolation.
- When the service needs to scale differently than or independently from the main applications. If so, it may be better to deploy the feature as a separate service.
Example
The sidecar pattern is applicable to many scenarios. Some common examples:
- Infrastructure API. The infrastructure development team creates a service that's deployed alongside each application, instead of a language-specific client library to access the infrastructure. The service is loaded as a sidecar and provides a common layer for infrastructure services, including logging, environment data, configuration store, discovery, health checks, and watchdog services. The sidecar also monitors the parent application's host environment and process (or container) and logs the information to a centralized service.
- Manage NGINX/HAProxy. Deploy NGINX with a sidecar service that monitors environment state, then updates the NGINX configuration file and recycles the process when a change in state is needed.
- Ambassador sidecar. Deploy an ambassador service as a sidecar. The application calls through the ambassador, which handles request logging, routing, circuit breaking, and other connectivity related features.
- Offload proxy. Place an NGINX proxy in front of a node.js service instance, to handle serving static file content for the service.
Ambassador Design Pattern
Create helper services that send network requests on behalf of a consumer service or application. An ambassador service can be thought of as an out-of-process proxy that is co-located with the client.
This pattern can be useful for offloading common client connectivity tasks such as monitoring, logging, routing, security (such as TLS), andresiliency patternsin a language agnostic way. It is often used with legacy applications, or other applications that are difficult to modify, in order to extend their networking capabilities. It can also enable a specialized team to implement those features.
Context and problem
Resilient cloud-based applications require features such ascircuit breaking, routing, metering and monitoring, and the ability to make network-related configuration updates. It may be difficult or impossible to update legacy applications or existing code libraries to add these features, because the code is no longer maintained or can't be easily modified by the development team.
Network calls may also require substantial configuration for connection, authentication, and authorization. If these calls are used across multiple applications, built using multiple languages and frameworks, the calls must be configured for each of these instances. In addition, network and security functionality may need to be managed by a central team within your organization. With a large code base, it can be risky for that team to update application code they aren't familiar with.
Solution
Put client frameworks and libraries into an external process that acts as a proxy between your application and external services. Deploy the proxy on the same host environment as your application to allow control over routing, resiliency, security features, and to avoid any host-related access restrictions. You can also use the ambassador pattern to standardize and extend instrumentation. The proxy can monitor performance metrics such as latency or resource usage, and this monitoring happens in the same host environment as the application.

Features that are offloaded to the ambassador can be managed independently of the application. You can update and modify the ambassador without disturbing the application's legacy functionality. It also allows for separate, specialized teams to implement and maintain security, networking, or authentication features that have been moved to the ambassador.
Ambassador services can be deployed as asidecarto accompany the lifecycle of a consuming application or service. Alternatively, if an ambassador is shared by multiple separate processes on a common host, it can be deployed as a daemon or Windows service. If the consuming service is containerized, the ambassador should be created as a separate container on the same host, with the appropriate links configured for communication.
Issues and considerations
- The proxy adds some latency overhead. Consider whether a client library, invoked directly by the application, is a better approach.
- Consider the possible impact of including generalized features in the proxy. For example, the ambassador could handle retries, but that might not be safe unless all operations are idempotent.
- Consider a mechanism to allow the client to pass some context to the proxy, as well as back to the client. For example, include HTTP request headers to opt out of retry or specify the maximum number of times to retry.
- Consider how you will package and deploy the proxy.
- Consider whether to use a single shared instance for all clients or an instance for each client.
When to use this pattern
Use this pattern when you:
- Need to build a common set of client connectivity features for multiple languages or frameworks.
- Need to offload cross-cutting client connectivity concerns to infrastructure developers or other more specialized teams.
- Need to support cloud or cluster connectivity requirements in a legacy application or an application that is difficult to modify.
This pattern may not be suitable:
- When network request latency is critical. A proxy will introduce some overhead, although minimal, and in some cases this may affect the application.
- When client connectivity features are consumed by a single language. In that case, a better option might be a client library that is distributed to the development teams as a package.
- When connectivity features cannot be generalized and require deeper integration with the client application.
Example
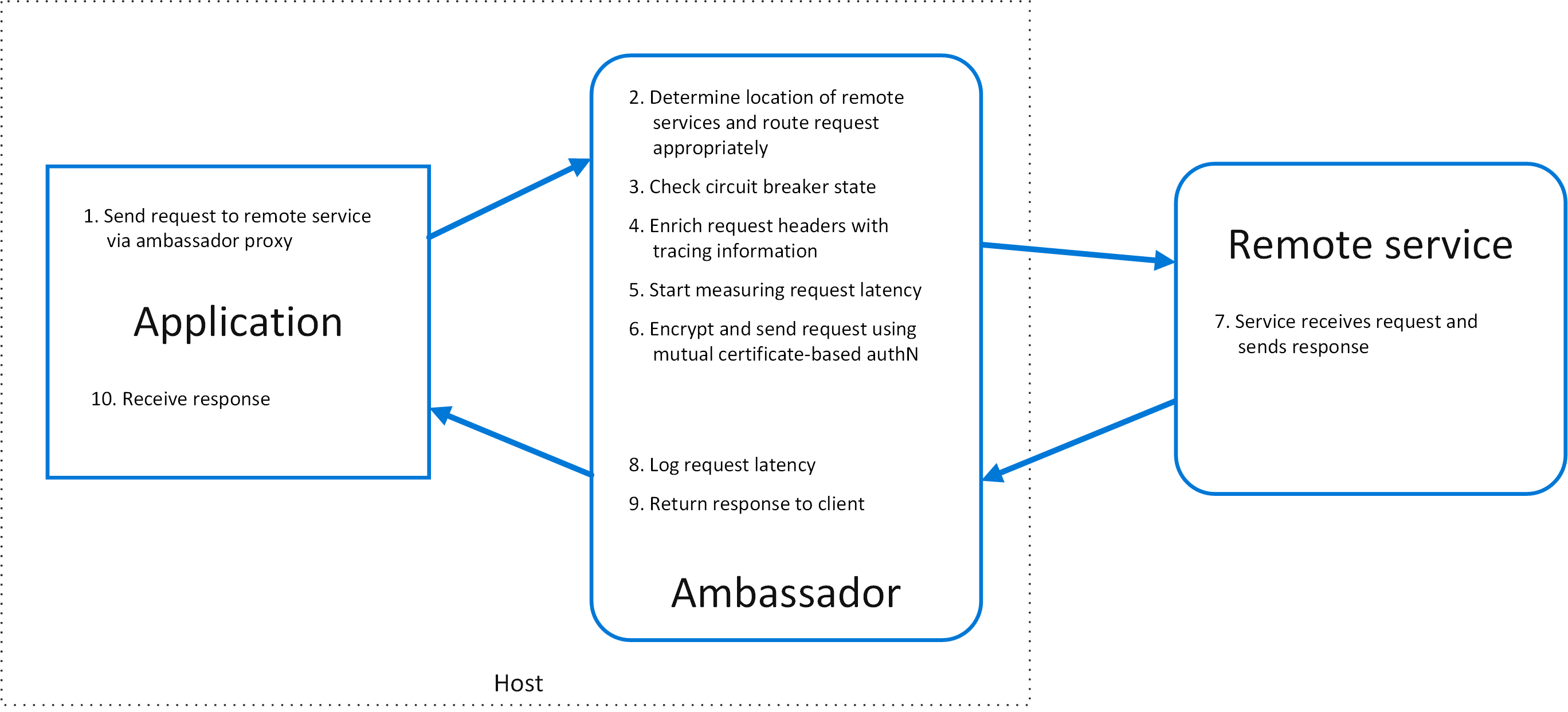
The following diagram shows an application making a request to a remote service via an ambassador proxy. The ambassador provides routing, circuit breaking, and logging. It calls the remote service and then returns the response to the client application:
Adapter Design Pattern
Adapter containers standardize and normalize output. Consider the task of monitoring N different applications. Each application may be built with a different way of exporting monitoring data. (e.g. JMX, StatsD, application specific statistics) but every monitoring system expects a consistent and uniform data model for the monitoring data it collects. By using the adapter pattern of composite containers, you can transform the heterogeneous monitoring data from different systems into a single unified representation by creating Pods that groups the application containers with adapters that know how to do the transformation. Again because these Pods share namespaces and file systems, the coordination of these two containers is simple and straightforward.

In all of these cases, we've used the container boundary as an encapsulation/abstraction boundary that allows us to build modular, reusable components that we combine to build out applications. This reuse enables us to more effectively share containers between different developers, reuse our code across multiple applications, and generally build more reliable, robust distributed systems more quickly. I hope you’ve seen how Pods and composite container patterns can enable you to build robust distributed systems more quickly, and achieve container code re-use. To try these patterns out yourself in your own applications. I encourage you to go check out open source Kubernetes or Google Container Engine.
Minority election mode
One of the common problems in distributed systems is the leader's election. Replicas are commonly used to share loads between multiple identical instances of a component. Another more complex role of replicas is that the application needs to distinguish between replicas and settings as "leader". The other copies are quick to replace the leader's position for quick copies if the previous copy fails. A system can even run multiple leader elections in parallel, for example, to define the leader of each of the multiple pieces. There are many libraries to run the leader election. It is difficult to understand, it is really difficult to use it correctly. In addition, their limitations are that they can only be written in a specific programming language. Another way to connect the leader library to an application is to use the leader to elect the container. The leader elects the containers, each with an instance of the application that wants the leader's election, and can be between themselves, and they can also present a simplified HTTP API on the local host to each application that requires the leader's election Program containers (eg, becomeLeader, renewLeadership, etc.). These leader containers can only be created once, and then the simplified interface can be reused by the application developer, regardless of what language they choose to achieve. In the field of software engineering, this is the best representative of the abstraction and encapsulation.
5.2 work quene mode

Although work queen is a well-researched project with the leader, because there are many frameworks to implement them, they are also examples of distributed system patterns that can benefit from a container-oriented architecture. In previous systems, the framework was limited to a single locale programming (eg, Celery for Python), or a work and binary distribution exercise left to the person who made it (for example, Condor). Implementing the container availability of the run () and mount () interfaces makes it easy to implement a generic work queen framework that can handle code that is packaged into containers in any process and create a complete work queen system. The developer can only choose to create a container that can process the input data file in the file system and convert it into an output file; this container will become a stage of the work queen. The way the user's code is integrated into this shared work queen framework has been described in Figure 4.
5.3 Scatter / gather mode

The last one to emphasize the distributed system model is Scatter / gather mode. In such a system, an external client sends an initial request to the "root" or "parent" node. The root of the request will be scattered to many of the many servers to perform parallel computing. Each fragment returns part of the data, root collects the data into a single response to the original request. This pattern is very common in search engines. The development of such a distributed system involves a lot of template file code: decentralized requests, collect responses, interact with clients, and so on. There are a lot of code that is generalized, again, just as in object-oriented programming, the code can be reconstructed in this way, and a single implementation can be provided. This method can also be used in any container, as long as they are implemented A special interface can be. In particular, in order to implement a Scatter / gather system, the user is asked to provide two containers. First, the container implements the tree structure end node; the container performs partial evaluation and returns the corresponding result. The second container is the combined container; this container takes the total production of all tree end nodes and returns them to a single group of responses.
Such a system is shown in Figure 5.
